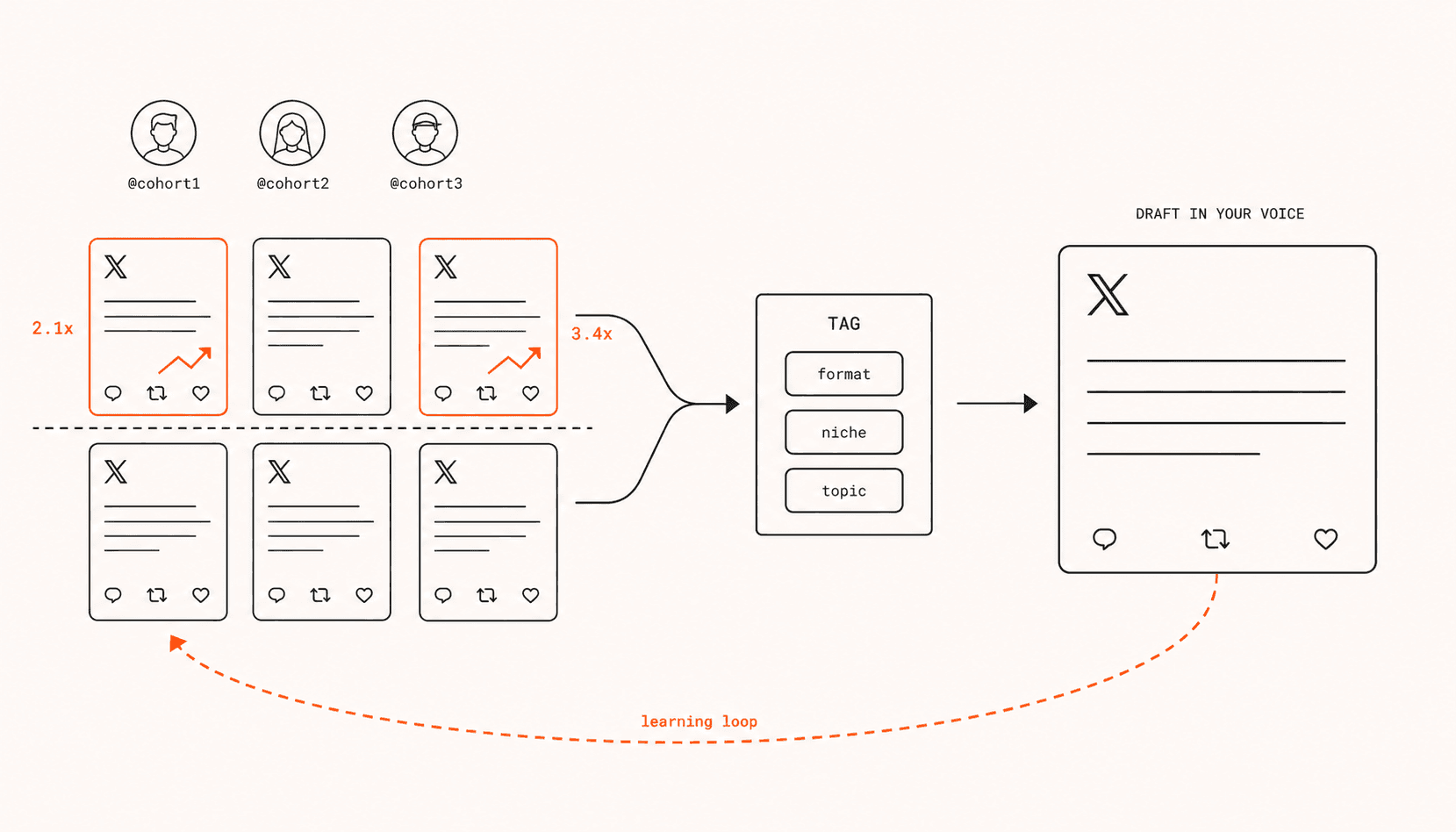
Most posts fail not because the writing is bad, but because the writer is guessing what the feed wants this week. The fastest way to stop guessing is to look at what is actually breaking out right now for accounts one step ahead of you in the same niche, and to draft from those patterns. That is the entire premise behind how ClimbX decides what to put on your calendar.
This post walks through the data pipeline behind a ClimbX draft: how we pick the accounts, what we count as an outlier, how the cohort refreshes, how the algorithm rules from our earlier algorithm post shape what gets drafted, and how the system gets sharper for you the longer you use it. Where I cite a number, it is either from the open-source X ranker or the actual production setting we run in ClimbX.
What we count as an outlier
An outlier is a post that materially beat the author's own baseline. The metric we use is a baseline multiplier: a post's impressions, replies, and reposts divided by the median of the 20 posts around it from the same author. A post at 1.5x is a clear win. 2x is an outlier. 3x and above is a breakout.
Anchoring on the author's own baseline matters because it normalises for account size, posting cadence, and time of day. A 5,000-impression post from a 2K account is a much stronger signal than a 50,000-impression post from a 500K account where the floor is higher. The ranker also reads engagement-rate signals at the author level, so a post that beat its own baseline by 2x is the post the algorithm itself flagged as performing.
Posts that hit the threshold get tagged for format (single, thread, quote, reply, poll), niche (one of the 50+ niches in the taxonomy), and topic keywords. Those tags are what the drafter retrieves against later. Raw text on its own would not be useful - it would tempt the model to copy phrasing, which is exactly what you should not do.
Why cohort-ahead, not viral accounts
The accounts a 2K-follower founder should study are not the same ones a 200K-follower creator should. A post that works for @levelsio at his current size leans on a reader pool that already trusts him. Replicating the same format from a 1K account gets nothing. The accounts that are actually instructive are the ones a couple of rungs up the ladder, where the playbook is still relevant to the smaller account's stage.
The cohort ClimbX picks for you sits at 2 to 5 times your current follower count, inside your declared niches. Three to five accounts maximum. Fewer is sharper. With a tight cohort the drafter learns specific shapes that work in your neighbourhood of X, instead of averaging across every popular creator and producing generic-feeling drafts.
Historical lookback also helps. The most useful examples from a 30K-follower account are often what they posted when they were at 5K, not what they post now. The data set we maintain logs follower-count snapshots on every cohort fetch, so the system can pull "what worked for @x when they were at your stage" rather than only the current moment.
How the polling works and why it stays cheap
The X API is pay-per-resource. Reading a post costs $0.005. Reading a user profile costs $0.010. Writing a post with a URL in it costs $0.200 - 40x the plain-write rate, which is one of the reasons scheduling URL posts is blocked in the composer. A single user watching five cohort accounts could easily burn $10 a month on polling alone if every fetch were per-user. The cost model only works because we share fetches.
When one user adds @sama to their cohort, the next 24 hours of @sama posts are fetched once and served to every other user with @sama in their list. With 100 users overlapping on the same handful of tech founders, per-user polling cost drops by two orders of magnitude. The cohort discovery layer is deliberately scoped to a curated list of growth accounts plus user-paste-in handles so the overlap stays high.
The cadence is adaptive. Accounts that posted in the last 24 hours get re-polled every 5 minutes. Inactive accounts throttle to once an hour. The data moat compounds quietly: every cohort fetch updates the follower-count log for that account, which feeds the historical lookback we just talked about, which feeds tomorrow's drafts.
How a draft actually uses the data
When you open the composer and ask for a draft, the drafter pulls a small set of recent outliers from your cohort that match the format and niche you indicated, then retrieves your last 100 to 200 posts as a voice corpus. The prompt the model sees is structured roughly like this.
- Voice block. Your last 100 to 200 posts in raw form, plus a summary the system maintains of the patterns that recur (sentence length, openers, closers, the words you actually use).
- Outlier block. 5 to 10 cohort posts with their baseline multiplier and tags. The instruction is explicit: learn the shape, the angle, the hook structure - do not reuse the words.
- Algorithm rules. The ranker's known behaviour, distilled to a short checklist (replyable hook, no link in the post, length appropriate to format, no AI-tell phrases).
- Your stories block. An optional set of personal specifics (projects, numbers, recent posts that worked for you) the model can ground a draft in. This is what stops the output from sounding like a generic AI summary.
The output is 2 to 3 draft variants per turn, each one explicitly tied to a different angle on the source outliers. You pick, edit, ship. The edit is mandatory - both as a quality bar and as a regulatory hedge against X tightening on undifferentiated AI content.
The X algorithm shapes the prompt, not just the post
A draft that violates the ranker's known preferences gets quietly buried no matter how good the writing is. The drafter respects three rules in particular, in the same order they appear in the algorithm post.
| Rule | How the drafter enforces it |
|---|---|
| Replies beat reposts beat likes | Every draft is checked for a replyable hook: a specific claim, contradiction, or a question with a real answer. Drafts that read as broadcast-only get rewritten. |
| No external links in the post | Hard-blocked. URLs in a scheduled post are rejected server-side. The composer proposes the link as a first-reply instead, which keeps reach on the original clean. |
| No AI-tell phrasing | No em-dashes, no "the truth is" / "here's the thing" openers, no hedged tricolons. The voice block is the counterweight: drafts default to your actual sentence shapes. |
The first 30 minutes after you post matter more than the next 24 hours combined, so the composer also surfaces a "post when your audience is online" suggestion based on when your previous outliers landed. That is the only real-time piece of the system right now; full reply-window alerts are scoped for v2.
The learning loop has two layers
A draft is not the end of the loop. Every post you ship feeds back into the system, and the system tightens in two directions at once.
Per-user personalisation
Your own performance refines the voice profile and the prompt over time. Posts that beat your baseline get higher weight in the voice block on the next draft. Drafts you edited heavily before publishing get diffed against the original so the model learns which patterns you reject. Posts you saved but never shipped are negative signal. The longer you use the system, the more your drafts look like the posts you actually want to publish, not the generic version.
Cross-user niche x size x type matrices
Every shipped post is anonymised and aggregated into a matrix keyed on niche, size band, and format. With enough users, the matrix answers questions like: "for a build-in-public account between 1K and 5K followers, do threads or single posts hit higher baseline multipliers right now?" The answer changes month to month as the ranker shifts. Cross-user data captures the shift faster than any single user could on their own. Individual posts never surface to other users; only the aggregated patterns do.
This is the two-layer moat. Per-user data compounds switching cost - your drafts get better with every post. Cross-user data compounds product quality - the drafts get better for everyone with every new user. The shape of this loop is closer to what NFX calls a data network effect than to a classic two-sided marketplace.
What the system deliberately does not do
Three temptations sit nearby this design that we say no to. Each one would either break the quality bar or break the unit economics.
- Auto-publish. Every draft gets a human edit before it ships. Voice drift on autopilot is the failure mode that kills the product positioning.
- AI-generated replies. Reply spam is the most algo-penalised behaviour on X. If you reply, you write the words. ClimbX surfaces timing and context, not text.
- Batch calendar generation. Pre-generating 30 drafts at signup would burn cost, age out before you posted them, and pull from a stale cohort snapshot. Drafts get made one at a time in the composer, against the freshest cohort data available that minute.
One short version
Pick three to five accounts a couple of rungs ahead of you in your niche. Watch what beats their own baseline. Write in your own voice, in the shape of what worked for them, while respecting what the ranker rewards. Ship, edit, learn from the result. Repeat. The whole pipeline is a way to do that loop with a fraction of the manual research, not a way to skip the writing.
Try the loop on your own cohort.
Pick three accounts you would like to be at in 12 months. ClimbX pulls their recent outliers, tags them, and drafts in your voice off what is currently working. Edit, ship, watch the loop tighten.
Read next
- How the X algorithm actually works in 2026. - Replies beat reposts beat likes. The 30-minute window decides everything. What the For You algorithm rewards now, and what it quietly suppresses.
Sources
- github.com/xai-org/x-algorithm - the open-source For You pipeline we read against when shaping prompts
- X API pricing - the per-resource costs the cohort-sharing math is built around
- NFX network-effects manual - the framing for why the cross-user matrix compounds the way it does